
Inspiration for embedding based mechanics for games and apps

Recently, I wrote a piece about vector embeddings that resonated. I’m humbled and thankful for all of you who read it and helped it reach the top of Hacker News. It reminded me how important it is to build in public and energized me to share about a game I tried to make last year with some mechanics that might inspire you.
Takeaways
Embeddings are lists of numbers in many-dimensional space that you can compare with trigonometry. Those numbers represent how similar things feel.
They’re great at mapping unbounded input to bounded output, specifically to records in your database.
Combining embedding ranking with odds makes a new category of game mechanics possible. I’ll show you some examples that I’ve built.

The Project
Around this time last year, I was working on Aimigo, my exploration into a generative AI Tamagotchi. Tamagotchis only have a few features: They eat, poop, play, get sick, misbehave, and grow up. I set out to build new variations of these mechanics to make something players felt they had a relationship with that wasn’t a romance-based chatbot. I guessed that a character with its own taste that showed you how to care for it would be compelling.
Embeddings
Vector embeddings are just lists of numbers, usually 0-1, representing coordinates in space. However, instead of 3-dimensional physical space, they often represent an idea space with thousands of dimensions. That can be difficult to conceptualize because the dimensions don’t represent tangible things like “brightness” or “mass.” While it’s frustrating that they’re a black box, close items semantically feel more similar, and far ones feel more different. Vector embedding distances are compared in a variety of ways. I used cosine distance because that’s what OpenAI embeddings were optimized for.
I’m drawn to embeddings because of how well they handle tasks that look like search. They can take arbitrary text requests and convert them into bounded output. For example, the icon search from the last article takes any string and returns a list of appropriate icons from our database.
Generally, I’ve found embeddings more helpful in building game mechanics than language models. Comparatively, language models were slow, expensive, and unreliable. The more I used them for business logic, the harder it was to test and ultimately ship. I did get value out of them for small targeted tasks. However, I had better luck combining embedding ranking and weighted odds for most of the game engine.
Feature 1: Choosing characters
Players encounter the first embedding mechanic in Aimigo when they create a character. I bought a set of animal models from the creator Omabuarts, with over 150 species and a consistent set of animations.1 Then, I had players describe their character’s personality and used that to determine the species of their character.
Since the actual character creation is not very eventful, I built this character chooser to make it more visual. You can try different descriptions for yourself.
Ranking possible species
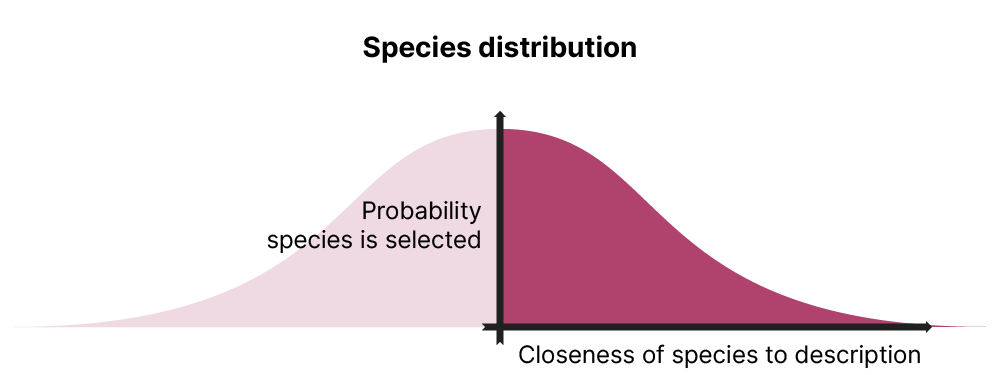
I asked the player to describe their desired character and converted that into an embedding. I had already calculated the embeddings for each species, which were ordered by their distance from the description.
This app is written in Elixir, which I’ve grown to love. I recognize Elixir is not the most popular language. Hopefully, the examples are simple enough to grasp through syntax.
characters = Repo.all(
from(c in Character,
order_by: [
asc: cosine_distance(c.embedding, ^description_embedding)
],
)
)This worked pretty well. The description “strong, brave, and heroic” is closest to a lion, whereas “brooding, goth, and dark” is closest to a crow. However, after playing with it, I thought the determinism diminished the fun factor. I didn’t want players guaranteed a species just because they knew the words to get them, so I inserted a little weighted randomness.
Odds for choosing a species
I got a lot of mileage from choosing a random number from a normal distribution. In this instance, I took the absolute value of a normal distribution. I centered it around 0 so species with short cosine distances were more likely to be chosen. 2
number_of_characters = length(characters)
index = floor(abs(:rand.normal(0, Math.pow(number_of_characters/6, 2))))
character = Enum.at(characters, index, Enum.at(characters, 0))The second input for a normal curve is variance (σ2), the square of standard deviation (σ), representing how wide or narrow the curve’s tails are. By adjusting it, I can tweak the relative likelihood for a player to get a species towards the beginning or end of the list. I divided the characters into six buckets of rarity.3

This weighted randomness gave me two features.
Players should feel like their description applies to the chosen species. Even if it’s not the top choice, all top options by proximity should be close to the right vibe.
If the species doesn’t match the description, that’s because something interesting happened, and that character is rare. A brooding crow will be much easier to get than a gloomy narwhal.
I wondered if I could skip this whole thing and instead feed the description and the list of possible species to a language model. Overall, I found that to be slower, more expensive, and less reliable. Prompting something like “Most of the time, give me the most intuitive species, but occasionally give me interesting unintuitive species” was ineffective. The embedding method is more predictable, inspectable, testable, and fun.
From then on, the character descriptions are fed into the language model for flavor text. When a player pets a grumpy character, it should respond less gratefully than a warm and fuzzy one. This should make the gloomy narwhal even more unique!
Feature 2: Feeding characters
The next mechanic I built lets players feed their characters.
The player offers their character a meal through a text input.
The character decides if they’ll accept it; if they do, they eat it and find out how much they like it.
The more they enjoy it, the happier it makes them.
Over time, they develop a taste for some foods over others.
I implemented this with a more complex version of my ranking and odds approach. The memory system I built was heavily inspired by a paper that had just come out about 8-bit sprite agents interacting in a small town: “Generative Agents: Interactive Simulacra of Human Behavior.”4
Ranking past experiences
When a player offers a character a meal, the meal is converted into an embedding to find relevant memories. This embedding search algorithm has three parts.
Cosine distance
Sort by the cosine distance between the embedding of the meal the player offered and the character’s memories of past meals. When players offer their character a calzone, they recall pizza more strongly than sushi.
Time decay
The second part of the algorithm biases towards more recent memories to ensure the character can grow over time. The general function is called exponential decay.

def time_decay(datetime) do
hours_ago =
DateTime.utc_now()
|> Timex.diff(datetime, :hours)
Math.pow(0.9995, hours_ago)
endI chose hours as the base unit. Then, I tweaked the rate of decay to see what felt right. I settled on a curve that flattened out at about a year.5
Subjective importance
The last part of the memory score evaluates how impactful each memory is to the character. More important memories should affect more decisions. Here is a targeted place where language models were effective. I asked GPT-4 how impactful it believed the memories were on a scale of 1 - 10.
message = """
On the scale of 1 to 10, where 1 is purely mundane
e.g., brushing teeth, making bed) and 10 is
extremely poignant (e.g., a break up, college
acceptance), rate the likely poignancy of the
following piece of memory.
Memory: #{memory.content}
"""The language model responded to adjectives and modifiers. For example, a character who likes cornbread is less enthusiastic about stale cornbread. If they enjoy sushi, they’re still weary of day-old sushi. The model also reacted well to the character’s species. A lion liked gazelle, whereas the herbivores did not.
The food-based memories mostly scored low in subjective importance; however, occasionally, they did not. I once fed my lion the bodies of my enemies, and they loved it. 9/10 core memory. When I fed them other food later, they’d say, “Meatloaf looks dull; I’m ready to feast on enemies!” or “Decent meal, but lacking the thrill of vanquished enemies.”6
Combined score
Cosine distance, time decay, and subjective importance are normalized to 0-1 and summed together to calculate the total retrieval score.
def normalize(value, max, min) do
(value - min) / (max - min)
endThe normalization function isolates the differences between the memories in the set by normalizing them between zero and one. This does two valuable things:
This makes scores with different ranges directly comparable. Otherwise, subjective importance with a rank of 1-10 would be so large that cosine distance would be irrelevant with a range of 0-1.
This isolates the differences between values. Even if cosine distance and time decay have possible ranges between 0 and 1, if the data for one are between 0.5 and 0.9 and the data for the other are between 0.3 and 0.5, the first might disproportionately influence the result.

Since there were only hundreds of memories per character, I fetched them from the database and scored them in the application code. It was easier to prototype, and the numbers were small.7 Whenever I needed memories, I did the initial scoring in Postgres with pgvector, then normalized and combined the scores in a reducer function.
Once the memories were ranked and sorted, I fed the top 15 memories into a language model with a prompt like “Given these experiences, how much do you expect to like tacos on a scale of 1-5?”8 This distilled the character’s expectation for a meal to a number I could put into the game engine to calculate the odds of getting different reactions from the character.
Odds for eating a meal
The odds mechanic also has two parts:
Does the character accept the meal
If so, how much do they enjoy it?
Both have similar mechanisms.
Odds of accepting a meal
def meal_accepted?(score) do
if :rand.normal(2, Math.pow(1.25, 2)) < score do
:accepted
else
:rejected
end
endThe app picks a random number on a normal curve centered at 2 with a standard deviation (σ) of 1.25. The character accepts the meal if the expected score exceeds the random number.
For example, when the character gives a meal an expected score of 1, they think they won’t like it. Most of the time, they’ll reject it without trying it. Conversely, if the character gives the meal an expected score of 5, they think they’ll like it a lot. They’ll rarely reject these. I centered the curve around two instead of three to bias characters towards trying things so players aren’t constantly rejected.
Odds of enjoying a meal
If the character accepts the meal, I calculate how much they liked it based on their original expected score.
def meal_enjoyment_score(expected_score) do
raw_score = :rand.normal(expected_score, Math.pow(1.25, 2))
cond do
raw_score < 1 -> 1
raw_score > 5 -> 5
true -> round(raw_score)
end
endI pick a number from the same normal curve as the last one. This time, I center it around the expected score and clean up the output so it’s always an integer of 1-5. A character is more likely to enjoy a meal if they thought they would. Their taste is influenced by past decisions but not determined by them.
Once that score is calculated, a few in-game things happen:
Memories of this meal are created with embeddings for strings like “Sparky thought they would like tacos” and “Sparky decided to eat tacos and loved it.”
The character’s happiness is updated based on how much they liked the meal
A flavor text response is created to communicate what happened to the player in a little speech bubble.
Create a record of how that meal was received. Players can see whether it was accepted or rejected, the actual vs expected score, and if you click into the meals, see what meals they were thinking about when they ate it.
Conclusion
I had a bunch of vague ideas for where to go next. The characters’ personalities could change based on how players treat them. If you left them starving, they wouldn’t be as friendly. Get some pseudo-nutrition information so they grow differently depending on whether they get protein or sugar.
None of these necessarily felt impactful enough to make players build a strong enough relationship with their character to want to care for them every day, the way people bonded with the original Tamagotchi. Ultimately, I lost steam. However, I hope these mechanics will inspire your projects. Aimigo was rough around the edges, but there’s a kernel of something exciting here.
I hope some of the work I did here inspires you. If it does, I’d love to see what you build. Send me a note or tweet at @ba_wolf.
Here is a summary of my implementation decisions and some sources for other options.
Vector database
I chose pgvector/Postgres, but there are plenty of other choices, including some for other standard databases like MongoDB.
Pgvector client
The elixir library for use with Ecto. You can find a library for your client of choice here.
Database host
This app is hosted by fly.io, though their option wasn’t really a managed instance at the time. Now, they have a managed solution with Supabase. If you want to look up someone else, Pgvector has a clumsy list of hosts that support it in this git issue.
Embedding model
Initially, I used OpenAI’s `text-embedding-ada-002`, but since writing this, I have upgraded them to OpenAI’s `text-embedding-3-small`. If you want to try something else, check out Huggingface’s leaderboard.
Distance metric
I used cosine similarity as our distance function because that’s what OpenAI recommends for their embeddings. Other embeddings may be optimized for different strategies. Pgvector supports l2 distance, inner product, and cosine distance.
Since I don’t need negative numbers, I take the absolute value of the curve, making it effectively only a big hump with a long right tail. I take the floor since I want integers to represent indices in a list. You can see this visualized on the character chooser
If I got any value index the size of the list, I assigned it to the first item on the list
This could easily be different, though. The simulacra agents’ memories were dramatically shorter.
I also asked a character to eat broken glass once, which registered a 9/10 when they ate it. They remembered that when being offered any other foods for a while, which, darkly, modeled trauma. Yikes.
Down the road, I’d probably have wanted to revisit this.
I would have loved to use an embedding-first approach, but I couldn’t think of something flexible enough to handle novel input.