
Breaking into Vision
Fine-tuning a vision model to recognize break dance power moves

I’ve been looking for a way to combine software engineering with my break practice and stumbled upon the idea of fine-tuning a vision model on power moves. Having never worked with vision, I really enjoyed it. Working with video data feels as close to working with atoms as you can with pure software.
The best parts were learning about:
Building a good dataset. No dataset is perfect, and mine was particularly limited by what I was willing to curate manually.
Training a model. The basic terms and moving parts.
When to lean on AI tools, especially Cursor, and when to ask a real person for advice.
If you want to skip all the details and try the model, you can do so at https://breakingvision.bawolf.com/. I hosted the best version on Replicate and made a small web app to help you cut and run clips against the model.
Data
I started with what I already had: a phone full of videos from practice. I omitted references where I fell or crashed and kept the scope small, narrowing down to three moves I had the most repetitions of. These were windmills, halos, and swipes. If you’re not familiar with power moves, that’s totally fine. Here are some examples:

A windmill 🌪️ was designed to be a continuous backspin. In practice, it’s a spinning roll on your back, head, and hands.

A halo 😇 is an off-axis head spin on your hands and head. You’re supposed to travel around a ring (halo) on your head.

A swipe 🤸 is a little more complicated but involves rotating your hands and one foot in a continuous circular cartwheel.
Without experience with labeling tools like CVAT or Label Studio, I uploaded videos to my computer and used LosslessCut to separate the videos and segment the individual moves into clips. The clips above are examples of what the model saw.
Sources
In addition to my phone clips, which I’ll call Bryant, I also made a second data source, which I’ll call YouTube.
Bryant
These are all videos taken from my phone. Most are from a single location over many practice sessions with slightly different angles. Some are repeated combos of the same move, while others are sequences of different moves. I was the subject of all of these videos.
YouTube
These are primarily educational tutorials from YouTube. I could reliably get many examples of a move from a single tutorial video, which made the cutting and labeling process much more manageable. A few of them are from battles or people’s training sessions. Unlike Bryant, these examples are primarily strings of one move but include examples from many different people and settings.
With between 300 and 400 examples of moves, both data sources are on the small side.1
Datasets
I arranged the sources into different datasets to understand how that would impact training. The goal is a model that generalizes, which means that it extrapolates to data it has never seen before. Some models appear promising but overfit, meaning they got good training scores but don’t hold up outside of what they were trained on.
Structure
Each dataset sorts videos into three buckets. My original data gathering was a bit unbalanced. I labeled way more clips of windmills than swipes or halos. I ended up shelving a bunch of extra clips to make sure I had an approximately equal amount of windmills, halos, and swipes:
70% into the training set used by the model for the learning process, making predictions, and inserting entropy to determine how to change its predictions in the future.
20% into the validation set the model uses to measure snapshots of how training is going without updating the model.
10% into the test set that measures how training went after completion.
Lastly, these clips had dimensions that were all over the place. Some were portraits, others were landscapes, and some were even squares. Clips were between 0.5 seconds and 3 seconds. I normalized them all to 224x224px squares at 30 fps, which seemed standard.
Permutations
Some of these are from the same combo in the original source video, which can disguise some problems down the road. If there are different windmills from the same practice session in both train and val sets, the model might cheat and learn that white walls or a chair in the corner are a sign of windmills. That wouldn’t be visible in the test scores, which would all look like they were passing.
I tried a few things to detect when that was happening. The most straightforward was training a model on Bryant and seeing if it generalized to YouTube and vice versa.
Next, I made an “adjusted” version of each dataset that tried to be a little cleverer. I sorted clips from the same source video into the same bucket. If a video had three windmills in a row, the first windmill could not be in the training set if the second windmill was in the validation or test set. This is a sample video of a chain of halos.
I also included clips from videos with more diversity in the training set. If a video had a loop of swipe, windmill, halo, swipe, windmill, halo, those clips had priority over clips from a video that looped halo, halo, halo. Here’s an example of a diverse source that contains windmills, halos, and swipes.
YouTube and Bryant had a random version with all the clips randomly distributed and an adjusted version with the above criteria. I also made combined random and combined adjusted datasets, which are made the same way but with both sources combined.
As an aside, One thing I didn’t expect from using cursor was how many more one-off scripts I had it make. Most of the sorting code was written almost entirely by cursor, including the code to create charts and tests that the sorting was correct.
Training process
If, like me, you have never trained a model, here’s a quick primer. Training is measured in epochs or the number of passes through each training example. The amount of examples the model looks at simultaneously is called the batch size. There is an explore/exploit trade-off when choosing a batch size.
Smaller batches are better at exploring. They have more variance within an epoch. They’re risky because they’re more likely to move away from a promising solution even when they’re close to one. In return, they can jump out of enticing wrong solutions toward better ones. They typically train slower because they don’t fully utilize GPU parallelization and memory.
Larger batch sizes are better at exploiting. They look at more data simultaneously, creating less variation between batches within an epoch. This is more stable, making them better at refining a good solution but more likely to get stuck somewhere non-optimal. They train faster by taking advantage of GPU parallelization when available.
Training produces weights. Think of them like constants in the model’s functions. When training from scratch, the model starts with random weights and shifts them each epoch. The amount it’s allowed to move them is called the learning rate. Typically, this starts high and shrinks at set epoch intervals. Fine-tuning a model is just doing more training but with your custom data on top of pre-existing weights called checkpoints.
Learning rate and batch size are just arbitrary values you set when you run the training process. In ML jargon, they’re called hyperparameters, which sounds more complicated and less approachable. Hyperparameter tuning is just running many trainings or fine-tunings with different values and seeing which produces the best model.
The weights of a model are really abstract. They don’t have direct meaning that a person can interpret. There’s no weight for the direction a person faces in a particular frame or a direct sense of how fast they’re moving. As a result, learning is a complex trial and error of changing weights and seeing the effect on learning. It can be unsatisfying initially, but it’s genuinely incredible that it works.
Training is measured in accuracy, the proportion of correct predictions over the number of total predictions, and loss, a measurement of how confident the model was in making those predictions.
At the end of every epoch, the training process calculates corrections to the weights that would have improved the model’s performance. This is called backpropagation. Individual corrections from any one epoch might only improve the model a little, but they add up over many repetitions.
After an epoch, the accuracy and loss are measured on the validation set without backpropagation to see if the model generalizes beyond the training set. Similarly, after training, the model is tested on the never-seen test set for a final measure.
Making a Model
It took me a while to get grounded. I started broadly, toying around with SAM2, pose libraries, and fine-tuning existing models. As a software engineer but not an experienced ML practitioner, there was a lot of clunkiness, and I ended up with many false starts.
Not all models from papers have public code, and even if they do, not all have documented processes for training and fine-tuning. Some have open weights, but others don’t. I clicked broken links that once led to checkpoints or raw datasets. Even understanding the format the model expected the dataset in could be opaque.
I have a web development background but am not an experienced Python developer. I had to do more version management finicking between Cuda, Conda, and Pip than expected. Overall, dependency management feels fractured in Python.2 I missed my `package.json` or `mix.lock` files. It was humbling.
Perplexity, ChatGPT, and Cursor were all bad at helping me choose which model to fine-tune. They were not very helpful in translating jargon or understanding how training might work from a code repo.
Eventually, I stepped back and worked with Cursor to build a simple model from scratch, which got me in the right groove. Cursor suggested a 3DCNN. The 3-dimensions are length, width, and time. CNN stands for Convolutional Neural Network. Roughly, it describes the strategy of scanning through video pixels, looking for patterns with a cube of pixels at a time. Each step of the scan looks at n pixels of length, by n pixels of width by n frames. This model was only a single layer and didn’t generalize well. Still, going through the whole end-to-end process of training, measuring, and even some hyperparameter tuning really helped my understanding.
Results
Briefly, here’s a sense of what this model was capable of and how it’s measured. These examples are from a single trial of the Bryant-random dataset, but the results across all the datasets were similar.
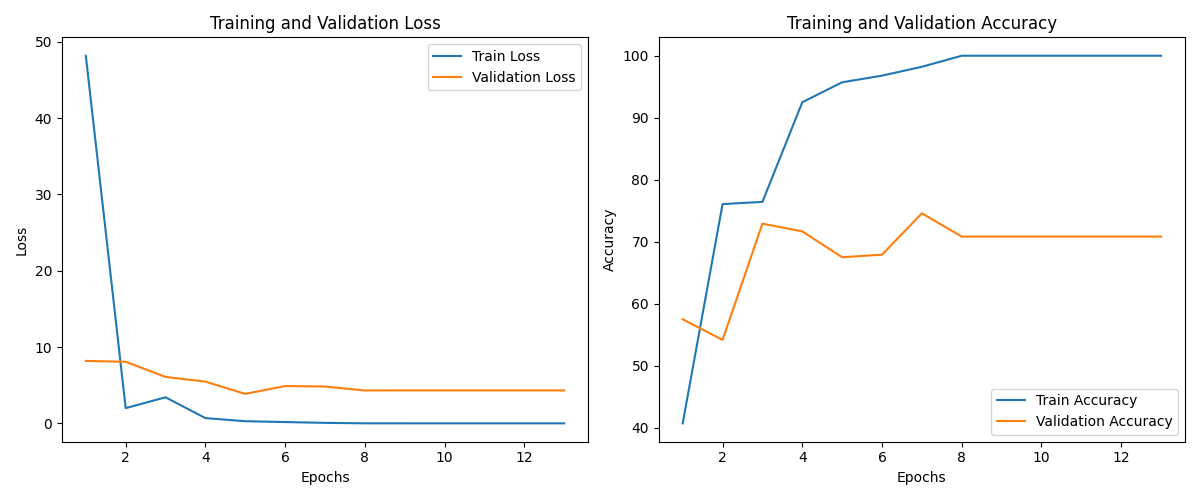
Despite becoming confident and 100% accurate in predicting training data after 8 epochs, the model was far less confident and only 70% correct in making predictions from validation data. This is a classic example of overfitting, where the model memorized the training data rather than learning patterns.
A confusion matrix shows the model’s predictions in more detail. The x-axis represents the model's prediction, and the y-axis is the actual value. [0,1,2] is a windmill, halo, and swipe.

If the model predicted all the values correctly, they would be in a diagonal line from top left to bottom right. Instead, the most consistent error was the model predicting that about half the swipes were aalos. I could go deeper, but this should be enough of a baseline to compare to the fine-tuning of CLIP.
Fine-tuning CLIP
Next, I took another swing at fine-tuning an existing vision model. There are models trained on massive datasets that understand human bodies. My videos would focus that knowledge on break moves.
Cursor was great at the low-level tactics of writing code, but human knowledge, whether from friends3 or Papers With Code, was much better at recommending base models than ChatGPT, Perplexity, or Claude. Simple questions like “Does this model take as input a video made up of a single move or multiple moves and an annotation file?” or “How should this data be formatted?” were more challenging for the AI tools to answer than I expected.
I settled on using a model based on OpenAI’s CLIP. Instead of 3DCNNs, CLIP uses transformers4, and instead of a single layer, CLIP uses many. CLIP was one of the fundamental breakthroughs in Dalle-2 and GPT-3. In their own words:
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3.
CLIP can only examine individual images. To augment it to understand videos, I naively grabbed 10-15 frames from each video and averaged out the feature vectors from each frame. A feature vector represents how much the model thinks the input is a windmill, a halo, or a swipe.
The middle of each clip tells more about which move is being performed than the beginning or end because there are multiple ways to transition in or out of a move. Windmill to windmill looks different than windmill to swipe. Understanding this, I grabbed frames over a normal distribution, with the majority closer to the center and fewer closer to the ends. The consequence of averaging is that there’s no information about the order of frames. The hard work is abstracted away into the clip model.
You can see this model for yourself here.
Results
I ran multiple training trials for each dataset to see which hyperparameters worked best. Overall, almost all of the models were better. They ranged from bad to okay to very good. The parameters with the most obvious positive impact on training were:
Use the large checkpoint. CLIP has multiple checkpoints that you can start from: the smaller `clip-vit-base-patch32` and the larger `clip-vit-large-patch14`. Almost all the good models were fine-tuned from the larger checkpoint. It’s bigger in several ways. The large model has 24 transformer layers, while the base uses 12. Those layers are based on vectors with more dimensions (1024 vs. 768), and as a result, the large model has way more parameters overall.
The best models unfroze 2-3 layers. You can unfreeze transformer layers from the top down when fine-tuning. The more you unfreeze the, the more malleable the model is to forget what it already knows and learn from the training data. Unfreezing one was too few, and the model wasn’t able to learn enough from the training data and got a lousy score in both training and validation, whereas unfreezing four allowed it to forget essential things about bodies and overfit to the training data, giving it good training scores but bad validation scores.
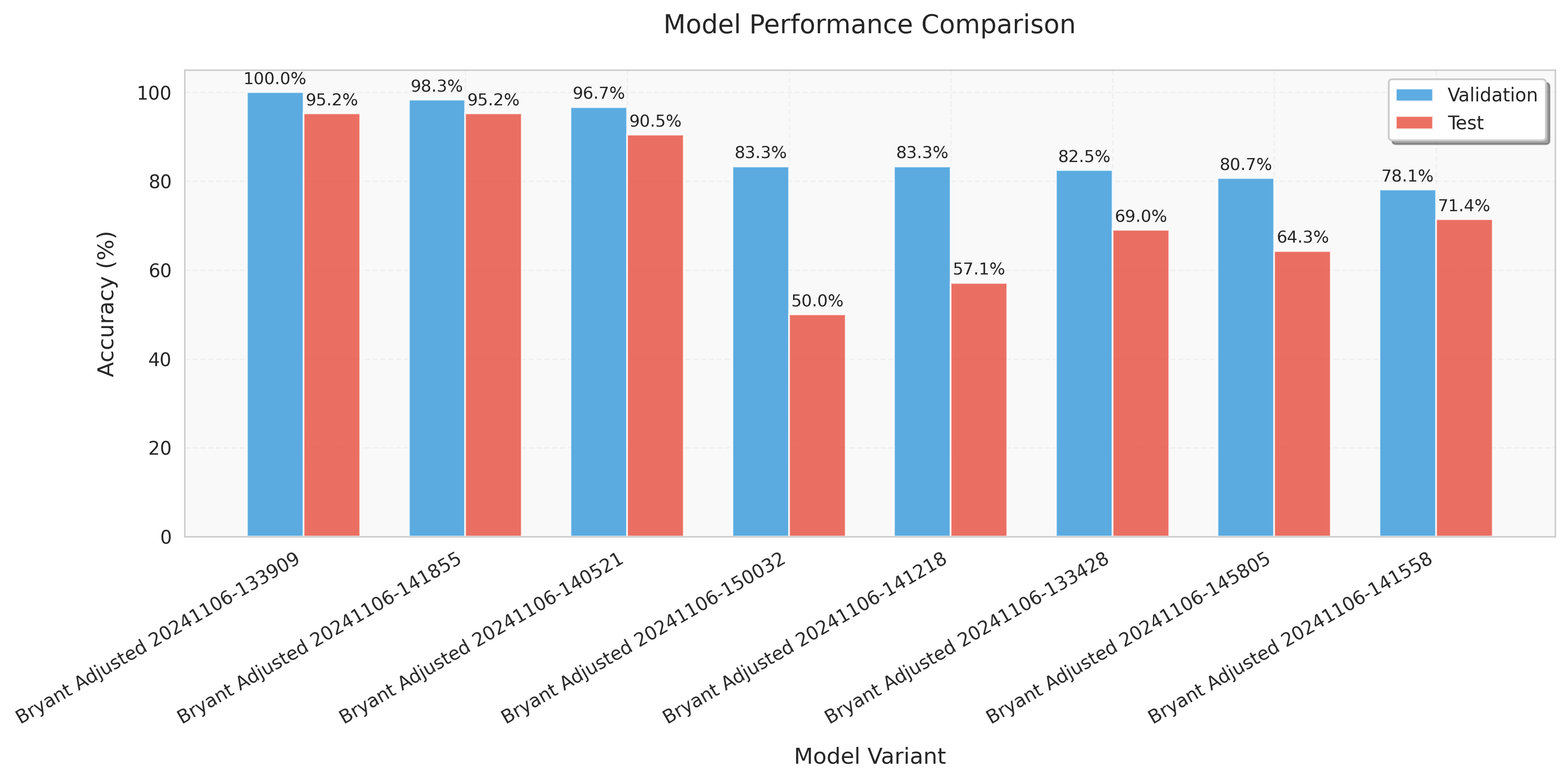
Some of these scenarios play out in the accuracy and loss of different models trained on the Bryant-adjusted dataset. The confusion matrices show which moves the models learned more or less correctly. The best model is good at labeling windmills and swipes but mislabeled halos as windmills or swipes once. Still, it's pretty good! I would take any of the top three models over the simple model from before.

The best models trained from each dataset were all very good, though the adjusted datasets were as good as or better than the random datasets.
Most of them are pretty good, but which one is the best? YouTube-adjusted had a pretty good claim, but since the top couple were so good that they were only missing a single example, I decided to run them against all the labeled clips I had, including the ones I’d cut out to make the numbers even early on.
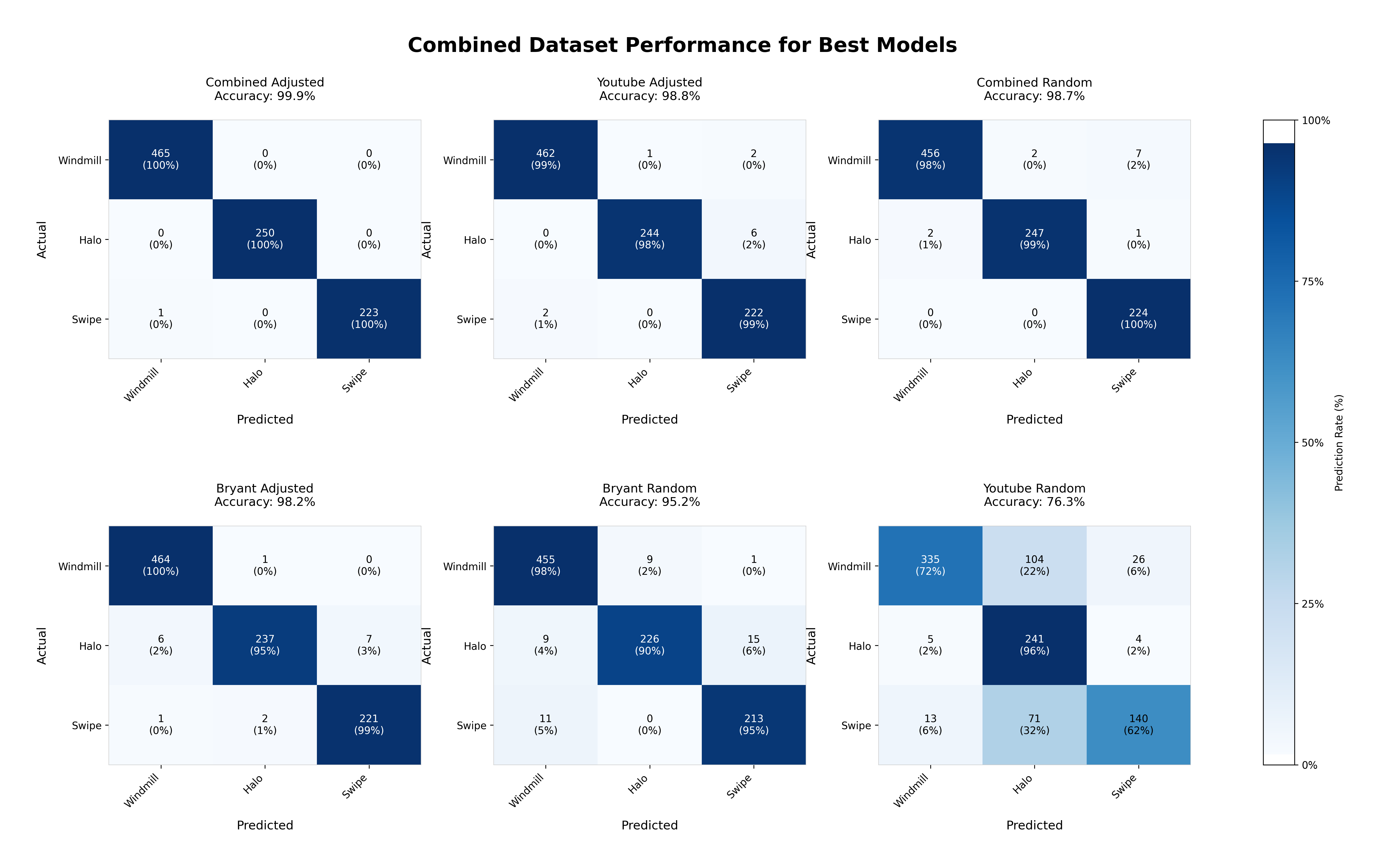
I was floored that combined-adjusted only missed one!5

The next closest model, our old winner, YouTube-adjusted, missed eleven. I declared combined-adjusted the winner.
If you break, I’m curious if it works for your clips, too! As a reminder, you can try it out here.
Conclusions
To be honest, I’m really impressed. These results were way better than I thought they would be. I’m not surprised that the combined training data was better than Bryant or YouTube, but I was surprised at how much better the adjusted sets were. Taking small steps to prevent these models from cheating seems to have gone a long way.
There are some obvious limitations here. This model only trained on three classes. There are hundreds of interesting break moves, and I don’t even know if the results would scale if you doubled classes to six or again to twelve. I’d love to try, but I might need some help labeling.6
This model has to label any input as a windmill, halo, or swipe. It would be interesting to train a model in a way that could say “none of the above” as an extra category and see how accuracy changed.
More than that, it would be better if this model had a sense of time. Feed it a longer video, and it labels the timestamps where moves occurred. The most interesting next step would be fine-tuning something like AdaTAD using OpenTAD. TAD stands for temporal action detection, the area of study around labeling what’s happening within videos.
All in all, this was really fun. It was empowering to see how far I could get on the shoulders of all the giants building great vision model tooling, the giants who built the great language models, and my friends. Approaching some of these topics can seem overwhelming at first, but there’s a lot of information out there now, so it’s more accessible than ever. You definitely don’t need an ML degree to try this out.
To squeeze more out of each image in these small datasets, an image might be rotated or have its brightness, contrast, or hue adjusted in training to ensure the model doesn’t focus too hard on those details.
Special thanks to Cinjon Resnik and Skyler Erickson! This might not have happened without you.
Explaining a transformer is outside the scope, but they’re the big breakthrough that powers language models. If you want to learn about them, I recommend this YouTube series.
You can kind of see how the last few frames might have influenced it to swing toward “halo.” There were fun experiences like this where it felt like you could “get” what the model was thinking intuitively.
If you’re interested, shoot me a note at breakingvision@bawolf.com.